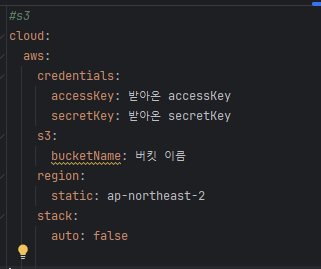
📦 Redis (Remote Dictionary Server) 란?
오픈 소스 인메모리 데이터 구조 저장소.
❓인메모리란?
데이터를 디스크와 같은 비휘발성 저장 장치가 아닌 주 메모리(RAM)와 같은 휘발성 메모리에 저장하는 방식.
- 빠른 데이터 접근 : 빠른 데이터 처리 속도 제공
- 휘발성 : 전원이 꺼지면 데이터가 사라짐
- 인메모리 데이터베이스 : 데이터를 메모리에 저장하여 빠른 속도로 데이터를 조회하고 처리함 (예 : Redis, Memcached, SAP HANA )
- 인메모리 저장소:
- Redis는 데이터를 메모리에 저장하기 때문에 매우 빠른 읽기/쓰기 성능을 제공한다. 이는 디스크 기반 데이터베이스보다 훨씬 빠른 성능을 제공하므로, 캐싱, 세션 관리, 실시간 분석 등 고속 처리가 필요한 애플리케이션에 적합하다.
- 다양한 데이터 구조 지원:
- Redis는 단순한 키-값 저장소 이상으로, 다양한 데이터 구조를 지원한다. 이를 통해 복잡한 데이터를 손쉽게 저장하고 조작할 수 있다.
- 영속성 옵션:
- Redis는 기본적으로 인메모리 데이터 저장소이지만, 데이터를 디스크에 저장하여 영속성을 보장할 수 있습니다. 이를 위해 RDB(Snapshotting)와 AOF(Append-Only File) 두 가지 방식이 제공됩니다.
- RDB: 특정 간격으로 데이터를 스냅샷으로 저장하는 방식
- AOF: 모든 쓰기 작업을 로그로 기록하여 장애 시 복구하는 방식
- 복제 및 클러스터링:
- Redis는 데이터 복제를 통해 고가용성을 제공할 수 있다. 마스터-슬레이브 구조를 사용하여 데이터를 복제하며, 슬레이브 노드는 읽기 작업을 분산할 수 있다.
- Redis 클러스터는 데이터 샤딩을 통해 여러 노드에 데이터를 분산 저장하고, 각 노드가 샤드의 일부를 관리한다. 이를 통해 수평 확장이 가능하며, 대규모의 데이터를 처리할 수 있다.
- 트랜잭션 지원:
- Redis는 간단한 트랜잭션 메커니즘을 제공하여, 여러 명령어를 원자적으로 실행할 수 있다. MULTI, EXEC, WATCH 명령어를 사용하여 트랜잭션을 구현할 수 있다.
Redis 설정
의존성 추가 - build.gradle
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
implementation 'org.springframework.session:spring-session-data-redis'
Redis 설정 파일 - RedisRepositoryConfig.java
public class RedisRepositoryConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
@Value("${spring.data.redis.password}")
private String password;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration();
redisStandaloneConfiguration.setHostName(host);
redisStandaloneConfiguration.setPassword(password);
redisStandaloneConfiguration.setPort(port);
return new LettuceConnectionFactory(redisStandaloneConfiguration);
}
}
application.yml 파일 설정
spring:
data:
redis:
host: localhost
port: 6379
Redis에 토큰을 저장하는 기능 추가 - JwtUtil.java
// Redis에 접근하기 위한 RedisTemplate을 추가
@Getter
private final RedisTemplate<String, String> redisTemplate;
public JwtUtil(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}public UserResponse.tokenInfo generateTokens(String userId) {
String accessToken = createAccessToken(userId);
String refreshToken = createRefreshToken(userId);
// Redis에 토큰 저장
saveTokenToRedis(userId, accessToken, refreshToken);
UserResponse.tokenInfo tokenInfo = UserResponse.tokenInfo.builder()
.grantType("Bearer")
.accessToken(accessToken)
.refreshToken(refreshToken)
.build();
return tokenInfo;
}private void saveTokenToRedis(String userId, String accessToken, String refreshToken) {
redisTemplate.opsForValue().set("ACCESS_TOKEN:" + userId, accessToken, accessTokenValidity, TimeUnit.MILLISECONDS);
redisTemplate.opsForValue().set("REFRESH_TOKEN:" + userId, refreshToken, refreshTokenValidity, TimeUnit.MILLISECONDS);
}public String refreshAccessToken(String refreshToken) {
if (validateToken(refreshToken)) {
Claims claims = getClaimsFromToken(refreshToken);
String userId = claims.get("userId", String.class);
//Redis에서 refreshToken 검증
String redisRefreshToken = redisTemplate.opsForValue().get("REFRESH_TOKEN:" + userId);
if (redisRefreshToken != null && redisRefreshToken.equals(refreshToken)) {
return createAccessToken(userId);
}
}
return null;
}
Redis와의 연동 - JwtInterceptor.java
@Component
@RequiredArgsConstructor
public class JwtInterceptor implements HandlerInterceptor {
private final JwtUtil jwtUtil;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws IOException {
String accessToken = request.getHeader(TokenType.ACCESS_TOKEN.toString());
String refreshToken = request.getHeader(TokenType.REFRESH_TOKEN.toString());
if (accessToken != null && jwtUtil.validateToken(accessToken)) {
String userId = jwtUtil.getUserIdFromToken(accessToken);
// 토큰 유효성을 검사할 때 Redis에 저장된 토큰과 비교하여 검증
String redisAccessToken = jwtUtil.getRedisTemplate().opsForValue().get("ACCESS_TOKEN:" + userId);
if (redisAccessToken != null && redisAccessToken.equals(accessToken)) {
return true;
}
}
if (refreshToken != null && jwtUtil.validateToken(refreshToken)) {
String newAccessToken = jwtUtil.refreshAccessToken(refreshToken);
if (newAccessToken != null) {
response.setHeader(TokenType.ACCESS_TOKEN.toString(), newAccessToken);
return true;
}
}
response.setStatus(401);
return false;
}
}
Redis 테스트
Redis 실행

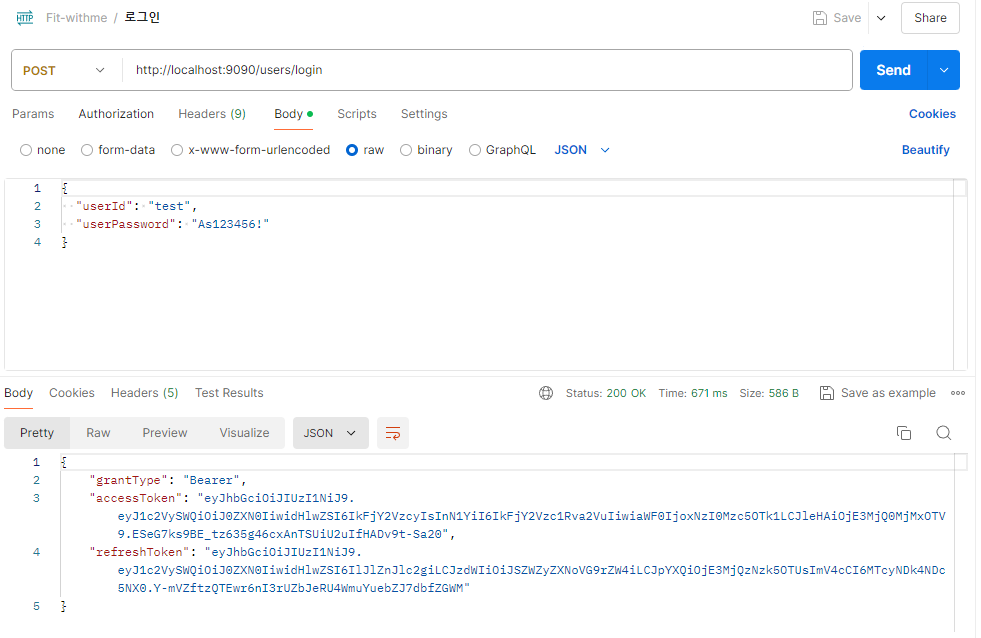
Postman에서 로그인 후 토큰 확인
Redis 데이터 확인 - redis.cli

'공부 > 프로젝트' 카테고리의 다른 글
| [AWS S3 / CloudFront] CloudFront로 이미지 캐싱하기 (0) | 2024.08.21 |
|---|---|
| [Spring / S3] Spring Boot 프로젝트 - S3 이미지 업로드 (0) | 2024.07.10 |
| [AWS S3] Spring Boot 프로젝트 이미지 업로드를 위한 S3 버킷 만들기 (0) | 2024.07.09 |
| Docker에 MySQL 설치하기 (0) | 2024.05.13 |